I made a web scraper and job posting manager
I built a web scraper earlier this week. It uses Sveltekit for the front/back end and SQLite for the database. Puppeteer is used to programmatically traverse the sites and extract the desired information. I can then edit the metadata, make notes about each job, and most importantly, check a checkbox to hide the job once I am done with it.
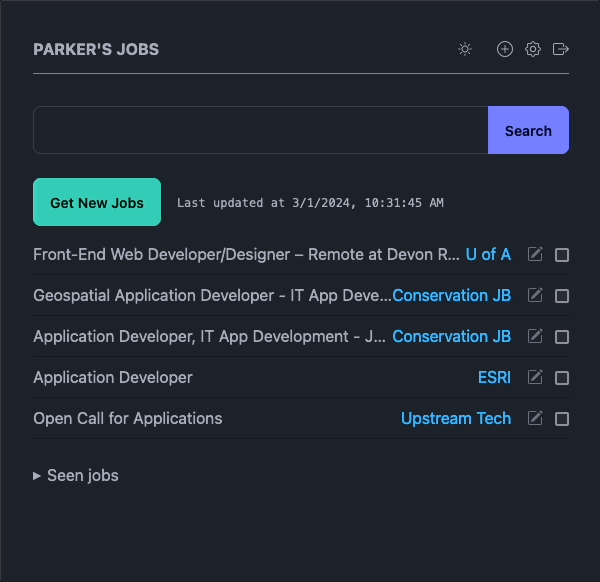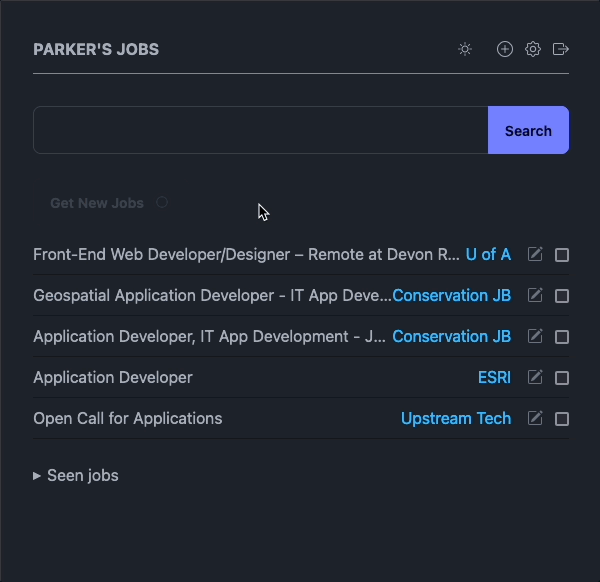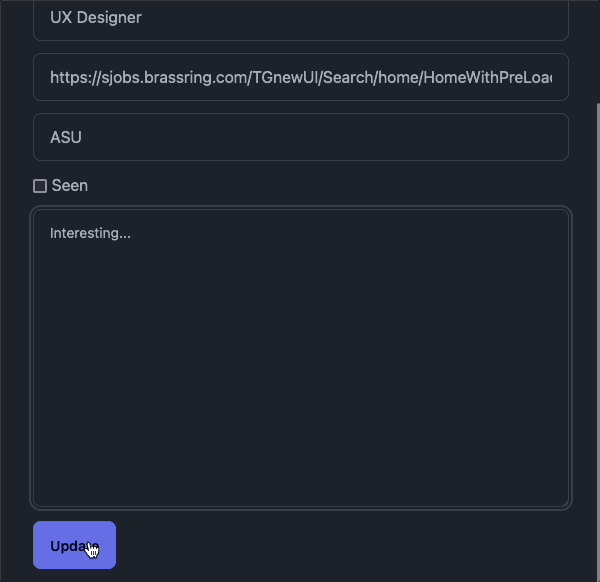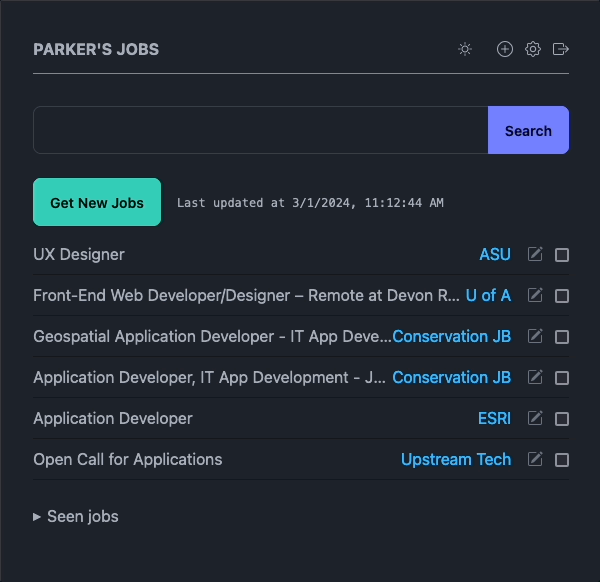
Each job board gets its own script file which handles the unique scraping logic for each site. I copy over the basic script for each job board then change the various querySelector() arguments for finding the job listing containers, titles, and link URLs.
For example:
import puppeteer from 'puppeteer';
export const getConservationJBJobs = async () => { try { const browser = await puppeteer.launch({ headless: true, defaultViewport: null, }); const page = await browser.newPage(); await page.goto( 'https://www.conservationjobboard.com/search/kw=%22application%20developer%22', { waitUntil: 'domcontentloaded', } ); await page.waitForNetworkIdle(); await page.waitForSelector('.listing__job'); const jobs = await page.evaluate(() => { const jobRows = document.querySelectorAll('.listing__job'); const jobsArray = Array.from(jobRows).map((job) => { const title = job.querySelector( '.listing__job__title' ).innerText; const link = job.querySelector('.listing__job__title a').href; return { title, link, board: 'Conservation JB', }; }); return jobsArray; }); console.log('Conservation JB----', jobs); browser.close(); return jobs; } catch (err) { console.error(err); }};Overall, it works great, saves time, and offloads a lot of mental energy. No more scanning over job boards, seeing jobs titled “Application Developer” that I know I’ve looked at before but can’t quite remember what the deal was, rereading the description and remembering, ah yeah, they need a Haskell developer, next.
Optimizations
I have no intention of actually making this a web app so the separation of client and server is probably an unnecessary over-complication. There’s no reason to make database calls only from the server if the server and client are both on my computer saving to a database on my computer. If I were to build it again, I might instead go SPA-style and use Tauri to make it a desktop app (no more revving up the dev server before running the app, precious seconds and keystrokes saved!).
When I click “Get New Jobs” it takes a bit of time to scrape through all the sites. A lot of this is unavoidable, scraping takes time, but there are some optimizations to be had.
In the first draft I had it iterating through an array of job scripts, scraping each site one after the other. Not the best.
for (const jobGetFunction of arrayOfJobGetters) { try { const jobs = await jobGetFunction(); jobs.forEach(async (job) => { if (!dbJobUrls.includes(job.link)) { await db.post.create({ data: { title: job.title, url: job.link, authorId: locals.user.id, slug: slugify(job.title.trim().toLowerCase()), }, }); } }); } catch (e) { console.log('ERROR!!!!!!', e); }}Now, it uses a Promise.all() to run all of the job scrapers in parallel, then once finished, loop through and add them to the database. Much faster.
try { const allJobs = await Promise.all(arrayOfJobGetters); if ([allJobs]) { const allJobsFlat = allJobs.flat(); allJobsFlat.forEach(async (job) => { if (!dbJobUrls.includes(job.link)) { await db.post.create({ data: { title: job.title, url: job.link, board: job.board ?? null, authorId: locals.user.id, slug: slugify(job.title.trim().toLowerCase()), }, }); } }); }} catch (e) { console.log('ERROR!!!!!!', e);}The next obvious optimization would be to take the best of both of these approaches and wrap each script in a write_to_database function so the data is saved immediately as it becomes available. Then each script runs in parallel and the data is immediately saved. This also allows the extracted data to be saved even if one of the other scripts throws an error. Maybe I’ll go do that right now…
…and here we go:
async function getJobsAndWriteToDatabase(jobGetter, dbJobUrls, userid) { try { const jobs = await jobGetter(); jobs.forEach(async (job) => { if (!dbJobUrls.includes(job.link)) { console.log('Writing new job to Database!', job); await db.post.create({ data: { title: job.title, url: job.link, board: job.board ?? null, authorId: userid, slug: slugify(job.title.trim().toLowerCase()), }, }); } }); } catch (e) { console.log('ERROR!!!', e); }}
// Sveltekit server action for API endpointexport const actions = { default: async ({ locals, request }) => { const dbJobs = await db.post.findMany(); const dbJobUrls = dbJobs.map((job) => job.url); const wrappedJobGetters = arrayOfJobGetters.map((getter) => getJobAndWriteToDatabase(getter, dbJobUrls, locals.user.id) ); await Promise.all(wrappedJobGetters); await db.updatedLast.update({ where: { id: 1 }, data: { updatedAt: new Date() }, }); console.log('\nFinished Getting Jobs\n'); redirect(302, '/'); },};Of course I could keep going and adding more features but for now this works great. The tool is built, now I’ve got to use it.
If you’re curious, you can find the git repo here: https://github.com/parkerdavis1/jobscraper/